
召回、粗排、精排联合建模
背景
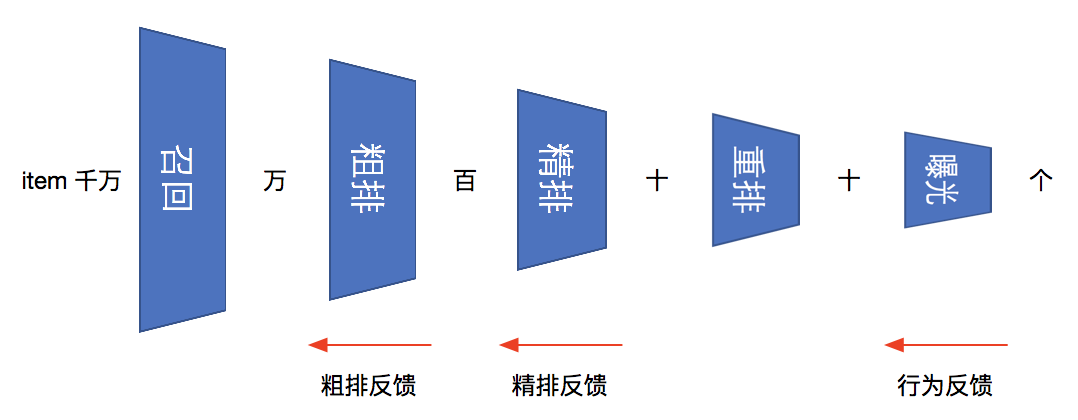
推荐漏斗由上图召回、粗排、精排、重排、曝光级联构成,item量级从千万到个逐级递减,同时获得从用户行为开始的逐级反向隐式反馈。
为了简化问题,这里暂不考虑重排反馈,直接将行为反馈作为精排输入,但实际上是需要考虑的。
一般情况下,召回、粗排、精排可能是三个小组在各自优化,没有考虑联合建模,简单使用用户行为反馈数据进行各自模型训练,这里会存在以下问题:
离线用户行为反馈数据vs线上实际预估数据,数据量级分布存在gap,影响模型效果,尤其对于召回和粗排
没有考虑联合建模,先不表多模型资源和维护成本,没考虑下游模型和数据反馈,对于召回和粗排在最终目标对齐上可能也有gap
方案
单任务
- 模型维度
有一拖二、一拖三、蒸馏等各种玩法,这里列举2个实用有代表性的:
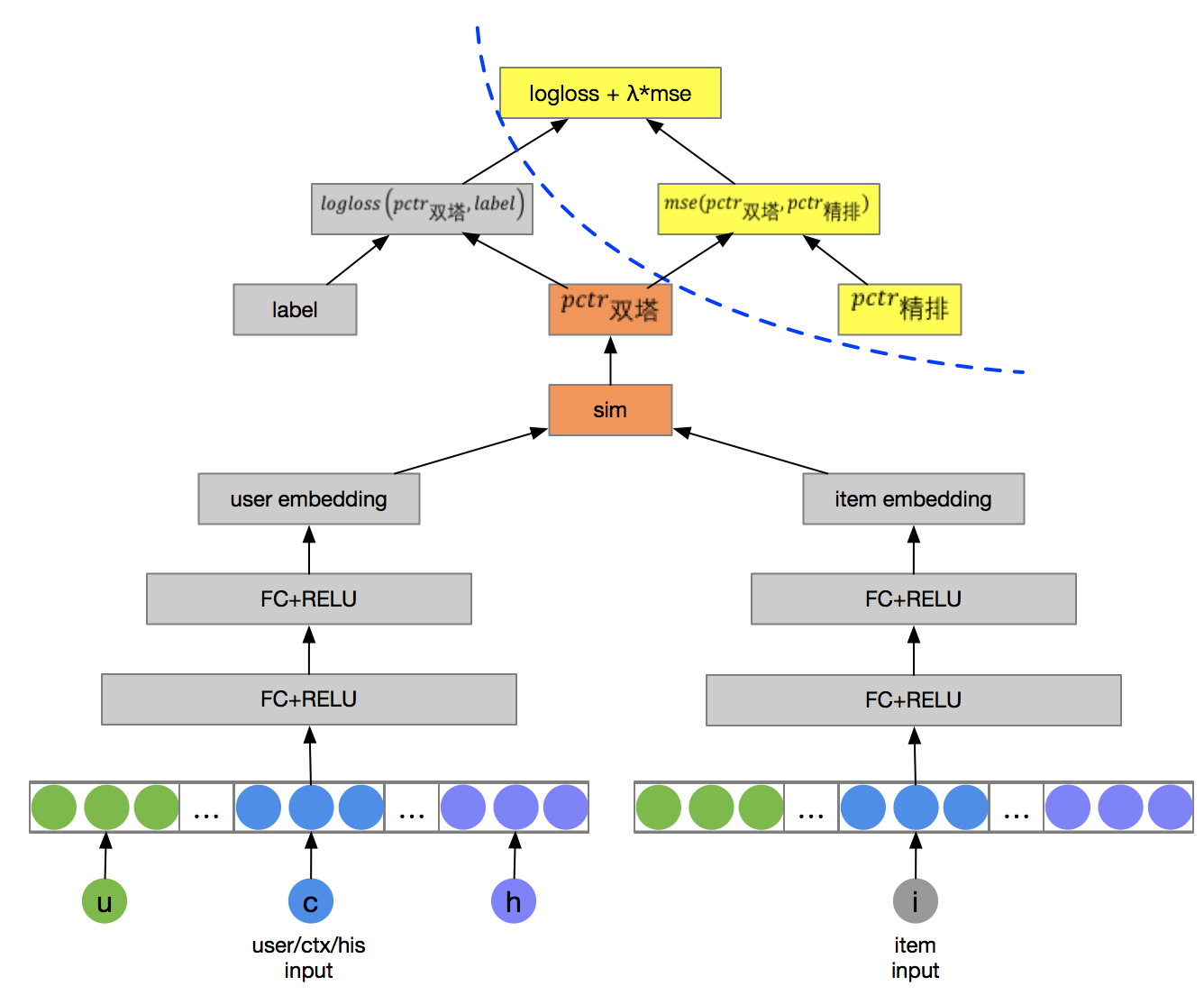
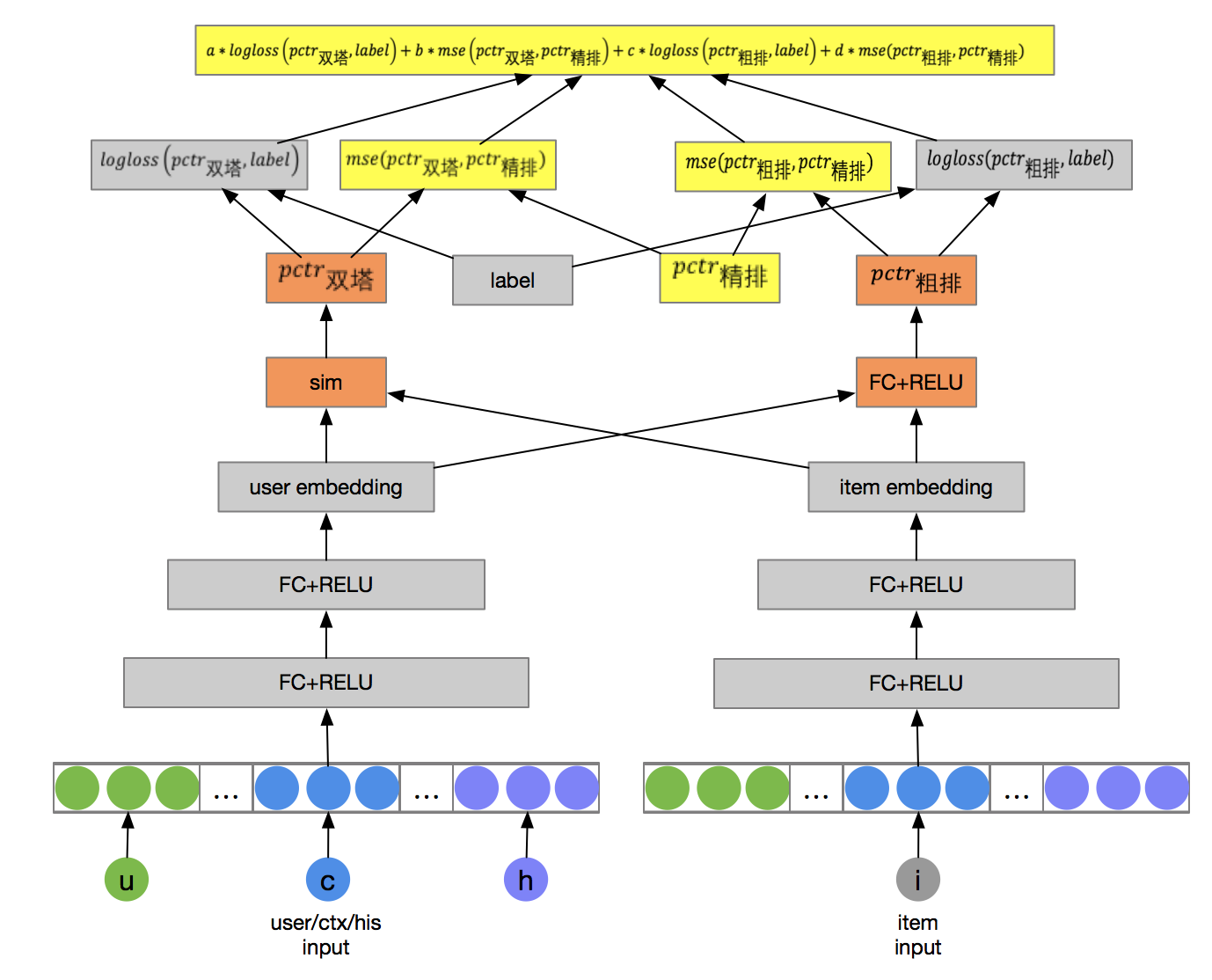
- 样本维度
利用下游的级联反馈可以补充有价值的正负样本,以召回为例:
负样本:可以将随机负采样、粗排尾部、精排尾部、曝光负样本按不同置信权重构建几个等级负样本。
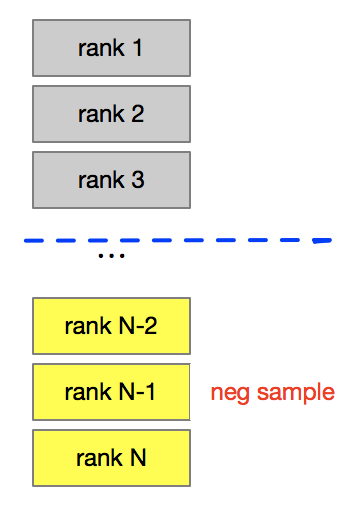
正样本:类似地,可以将粗排头部、精排头部、曝光正样本按不同置信权重构建几个等级正样本。
多任务
类比单任务,可以对多任务中每个目标进行单任务联合建模,然后在漏斗的每一层执行和重排一致的多目标融合。
另一种思路是,只训练一个综合模型,不以某个特定任务为训练目标,召回、粗排以多目标融合后头部为正样本,尾部及随机负采样为负样本。
