ParameterServer小结
18年搞了半年大规模分布式深度学习框架研发,那时细节还很鲜活,本该一年前写此文,奈何懒是原罪😓。本文仅针对parameter server部分进行highlight小结,距工业界可用分布式学习框架还差很多组件(数据流,算子,优化器,failover,servering等),不在本文范围。具体细节需参考相关paper和代码,本文更多是个人时间线上的备忘。
问题规模
数据
按100亿instance算,每个样本平均100个key,每个key 20B,共计20TB。
特征
按100亿feature算,每个feature kv占内存50B,共计500GB。
模型
DNN部分存储可忽略。
按6层FC算,网络宽度分别512-256-128-128-128-1,一次前向计算需要20万次float乘法。
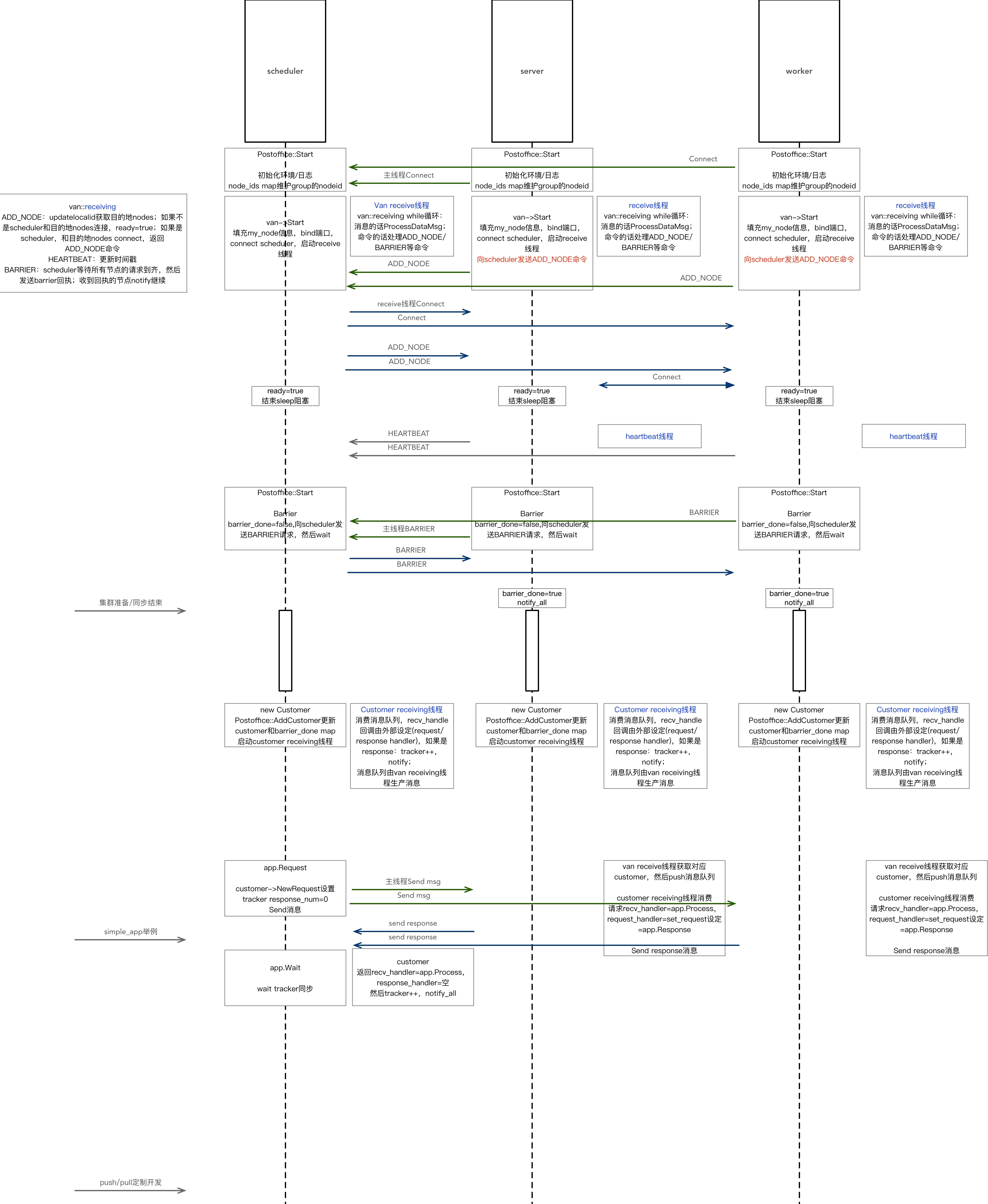
逻辑图
很好理解不展开,主要是异步。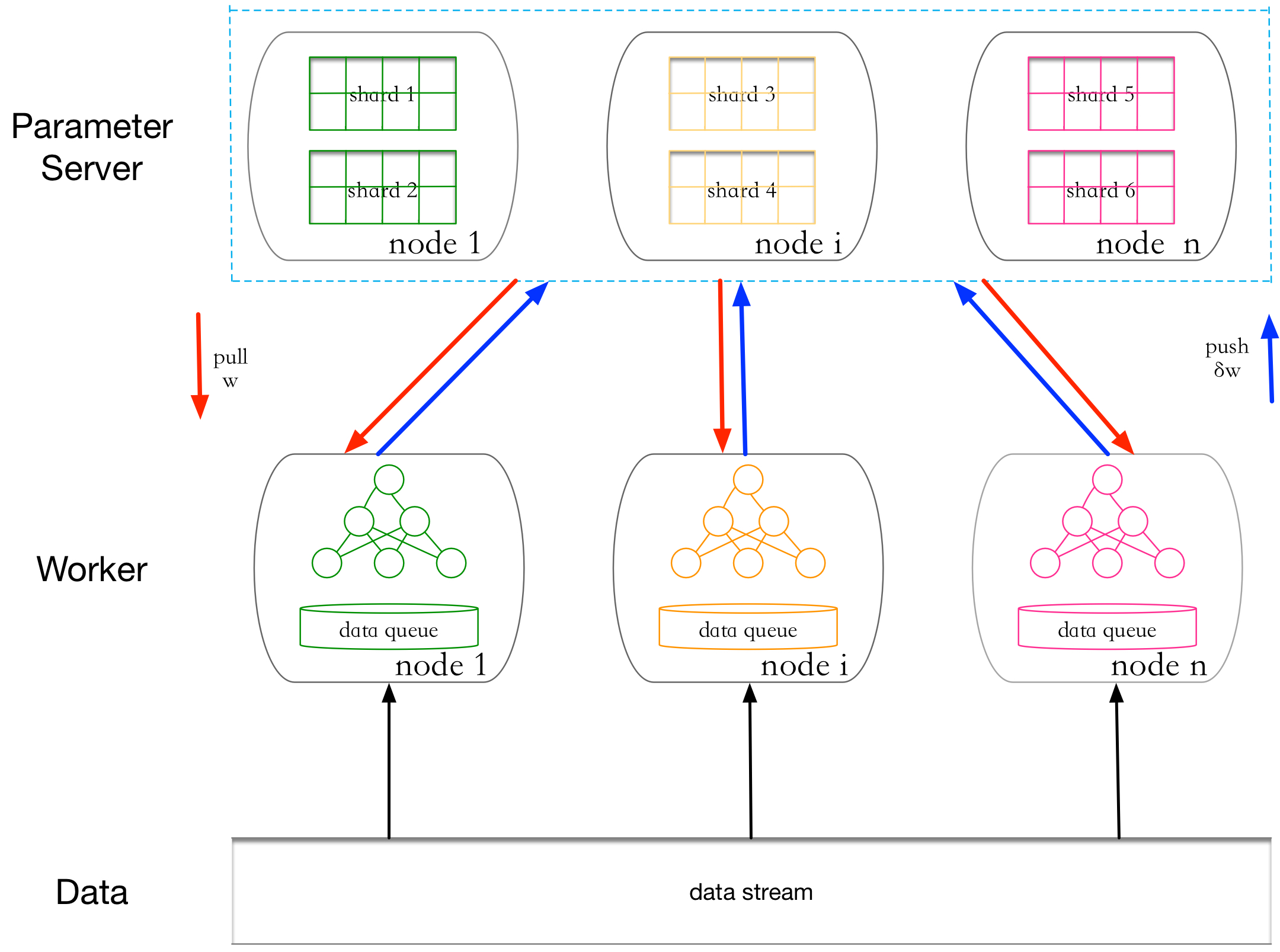
流程图
流程图如下图,可以抽象出以下模块:
异步离不开队列,这里抽象出channel,流转各种callback,类似go的channel;RpcServer作为生产者,customer thread group作为消费者,server端主要是request handler,worker端主要是response handler。
Table路由逻辑可以设计的比较简单,比如按余,这样可以取消proxy模块;线程组可以和table shard一一对应,可以简单无锁。
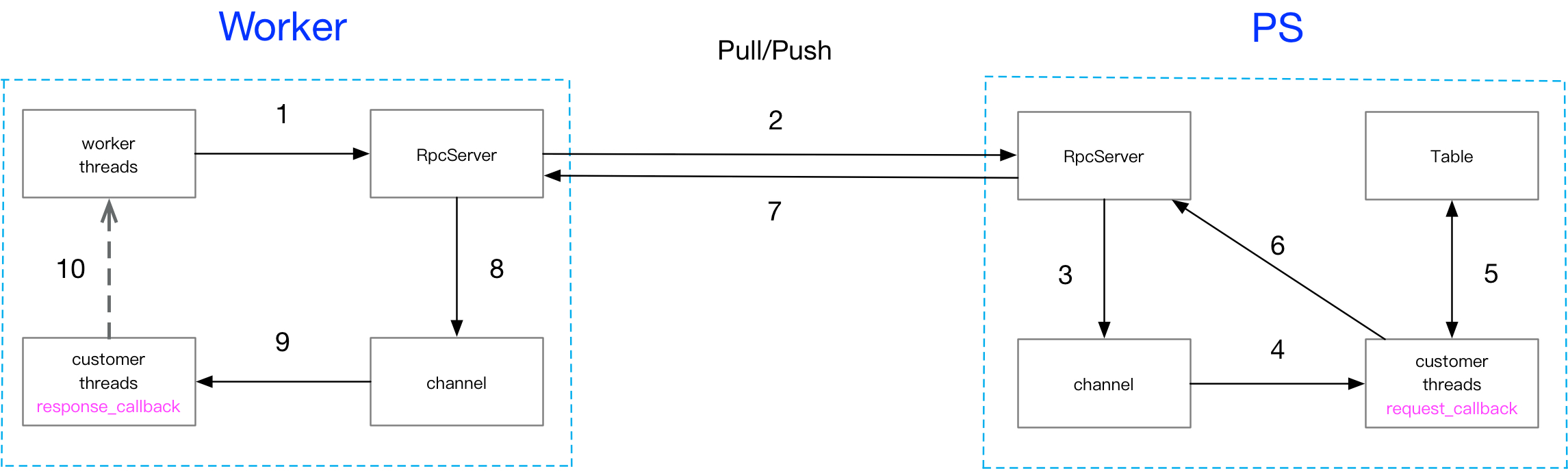
ps-lite时序图
这里以开源ps-lite为例,基本也是上图的抽象范式,同时引入了scheduler进行集群状态管理。barrier前主要是集群的准备/同步,具体的pull/push训练逻辑可以参考例子进行定制。