
Kaggle实战(二)
上一篇都是针对小数据集的,入门不建议从大数据集开始,可以不用考虑机器内存,不用out-of-core的online learning,不用考虑分布式,可以专注模型本身。
接下来我做了两个广告CTR预估相关的比赛,不过比赛当时都已经closed了,还好,我们还可以提交结果看看close时能排到的位置。
比赛实战
6. Display Advertising Challenge
Predict click-through rates on display ads. https://www.kaggle.com/c/criteo-display-ad-challenge
这是一个广告CTR预估的比赛,由知名广告公司Criteo赞助举办。数据包括4千万训练样本,500万测试样本,特征包括13个数值特征,26个类别特征,评价指标为logloss。
CTR工业界做法一般都是LR,只是特征会各种组合/transform,可以到上亿维。这里我也首选LR,特征缺失值我用的众数,对于26个类别特征采用one-hot编码,数值特征我用pandas画出来发现不符合正态分布,有很大偏移,就没有scale到[0,1],采用的是根据五分位点(min,25%,中位数,75%,max)切分为6个区间(负值/过大值分别分到了1和6区间作为异常值处理),然后一并one-hot编码,最终特征100万左右,训练文件20+G。
强调下可能遇到的坑:1.one-hot最好自己实现,除非你机器内存足够大(需全load到numpy,而且非sparse);2.LR最好用SGD或者mini-batch,而且out-of-core模式(http://scikit-learn.org/stable/auto_examples/applications/plot_out_of_core_classification.html#example-applications-plot-out-of-core-classification-py), 除非还是你的内存足够大;3.Think twice before code.由于数据量大,中间出错重跑的话时间成品比较高。
我发现sklearn的LR和liblinear的LR有着截然不同的表现,sklearn的L2正则化结果好于L1,liblinear的L1好于L2,我理解是他们优化方法不同导致的。最终结果liblinear的LR的L1最优,logloss=0.46601,LB为227th/718,这也正符合lasso产生sparse的直觉。
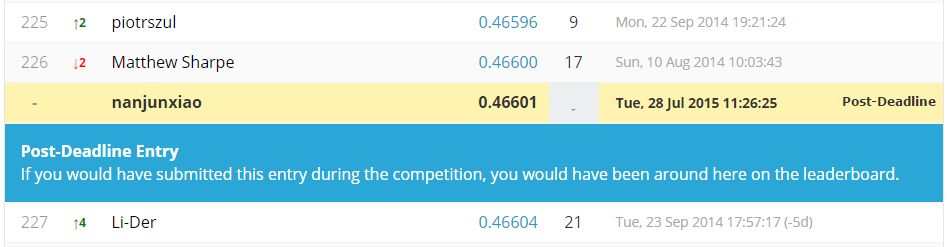
我也单独尝试了xgboost,logloss=0.46946,可能还是和GBRT对高维度sparse特征效果不好有关。Facebook有一篇论文把GBRT输出作为transformed feature喂给下游的线性分类器,取得了不错的效果,可以参考下。(Practical Lessons from Predicting Clicks on Ads at Facebook)
我只是简单试验了LR作为baseline,后面其实还有很多搞法,可以参考forum获胜者给出的solution,比如:1. Vowpal Wabbit工具不用区分类别和数值特征;2.libFFM工具做特征交叉组合;3.feature hash trick;4.每个特征的评价点击率作为新特征加入;5.多模型ensemble等。
7. Avito Context Ad Clicks
Predict if context ads will earn a user’s click. https://www.kaggle.com/c/avito-context-ad-clicks
跟上一个CTR比赛不同的是,这个数据没有脱敏,特征有明确含义,userinfo/adinfo/searchinfo等特征需要和searchstream文件 join起来构成完整的训练/测试样本。数据包含392356948条训练样本,15961515条测试样本,特征基本都是id类别特征和query/title等raw text特征。评价指标还是logloss。
由于数据量太大,跑一组结果太过耗时,根据比赛6的参考,目前我只选择liblinear lasso LR做了一组结果。最终目标是预测contextual ad,为了减小数据量,*searchstream都过滤了非contextual的,visitstream和phonerequeststream及params目前我都没有使用,但其实都是很有价值的特征(比如query和title各种similarity),后面可以尝试。
对于这种大数据,在小内存机器上sklearn和pandas处理起来已经非常吃力了,这时就需要自己定制实现left join和one-hot-encoder了,采用按行这种out-of-core方式,不过真心是慢啊。类似比赛6,price数值特征还是三分位映射成了类别特征和其他类别特征一起one-hot,最终特征大概600万左右,当然要用sparse矩阵存储了,train文件大小40G。
Libliear貌似不支持mini-batch,为了省事没办法只好找一台大内存服务器专门跑lasso LR了。由于上面过滤了不少有价值信息,也没有类似libFM或libFFM做特征交叉组合,效果不好,logloss只有0.05028,LB排名248th/414。
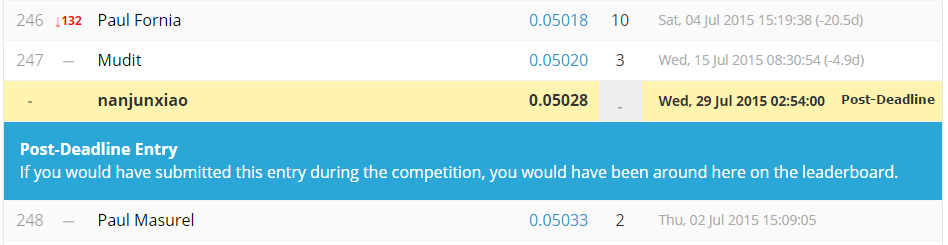
对于该比赛需要好好调研下大牛们的做法,看看相关paper了,自己瞎搞跑一遍太耗时间了,加油吧~
总结与感悟
通过参加kaggle提高了自己的机器学习实战能力,对问题和数据有了一些感觉,大致了解了各模型的适用场景。当然还有很多需要提高,比如特征组合/transform/hash trick,模型ensemble方法等,实现的scalable(比如采用pipeline)。
Ps:一定要挑选几个适合自己的高效工具包,并对其中2-3个看过源码,最好能做到定制优化。希望大家都加入到kaggle,欢迎一起探讨提高~
